A Continuous Integration and Continuous Deployment (CI/CD) pipeline is an automated process that helps deploy applications with little to zero manual effort. CI/CD pipelines are a critical part of a software development lifecycle, as a well-thought-out pipeline can foster speedy software delivery.
While there are several tools out there, both commercial and open-source, to help set up your CI/CD pipeline, in this article, we look at a particular tool called Spinnaker.
Developed by Netflix as an open-source, mult-icloud continuous delivery tool, Spinnaker was released as a successor to Netflix’s internally developed tool Asgard in November 2015. It supports most cloud-native platforms, including AWS, Azure, GCP, Kubernetes, and Oracle Cloud; Google currently also helps extend and maintain it.
Key features of Spinnaker include:
We will be installing Spinnaker on minikube using the Docker driver. Minikube is a single-node minimal Kubernetes cluster widely used for proof of concept purposes. You can set up a minikube cluster by following this guide.
Since Spinnaker consumes significant resources, i.e., a minimum of 4 cores and 8 GB RAM, let’s ensure that our minikube instance has that allocated:
minikube start --memory 8192 --cpus 4
Once minikube is up and running, you can install Halyard as a Docker container. Halyard is specially designed for configuring and managing Spinnaker. You need to install it in the minikube network because it will be interacting with the minikube instance:
docker run --name halyard -v ~/.hal:/home/spinnaker/.hal -v
~/.kube/config:/home/spinnaker/.kube/config --network="minikube" -
d gcr.io/spinnaker-marketplace/halyard:stable
Get a shell inside the Halyard container and confirm that you can run kubectl commands. Once we have Kubernetes connectivity, enable the Kubernetes cloud provider:
hal config provider kubernetes enable
For Spinnaker to be able to access objects in the cluster, you will need a Kubernetes account, which we have enabled with the account name “spinnaker-test” using the following command:
hal config provider kubernetes account add spinnaker-test --
provider-version v2 --context $(kubectl config current-context)
Now, associate your Kubernetes account with Halyard:
hal config deploy edit --type distributed --account-name
spinnaker-test
Next, configure a persistent storage for Spinnaker. Here we’re using S3 buckets to enable persistence but you can use MinIO as well:
hal config storage s3 edit \
--access-key-id "<Access Key ID>" \
--secret-access-key \
--region us-west-2
hal config storage edit –type s3
You will also need to choose a version of Spinnaker to install:
hal config version –list
hal config version edit –version <selected-version>
Finally, to install Spinnaker:
hal deploy apply
Getting all the Spinnaker pods up and running will take some time. Once they’re up, we need to make some final configuration changes with regard to the dashboard. To access the dashboard from your browser, convert the spin-deck and spin-gate services in the Spinnaker namespace as nodeport services, where spin-deck service is the actual UI endpoint of spinnaker and spin-gate service is the gateway endpoint which needs to interact with the UI endpoint and set the URLs in the Halyard config.
To expose the nodeport services:
kubectl patch svc spin-deck --type='json' -p
'[{"op":"replace","path":"/spec/type","value":"NodePort"},{"op":"replace","path":"/spec/ports/0/nodePort","value":30010}]' -n
spinnaker
kubectl patch svc spin-gate --type='json' -p
'[{"op":"replace","path":"/spec/type","value":"NodePort"},{"op":"replace","path":"/spec/ports/0/nodePort","value":30020}]' -n
spinnaker
To set the URLs:
hal config security ui –edit –override-base-url
“http://<minikube-ip>:30010”
hal config security api –edit –override-base-url
“http://<minikube-ip>:30020”
hal deploy apply
To create a basic CD pipeline, where we can deploy NGINX and a clusterIP service leveraging Spinnaker, navigate to the dashboard and click on “Create Application”:
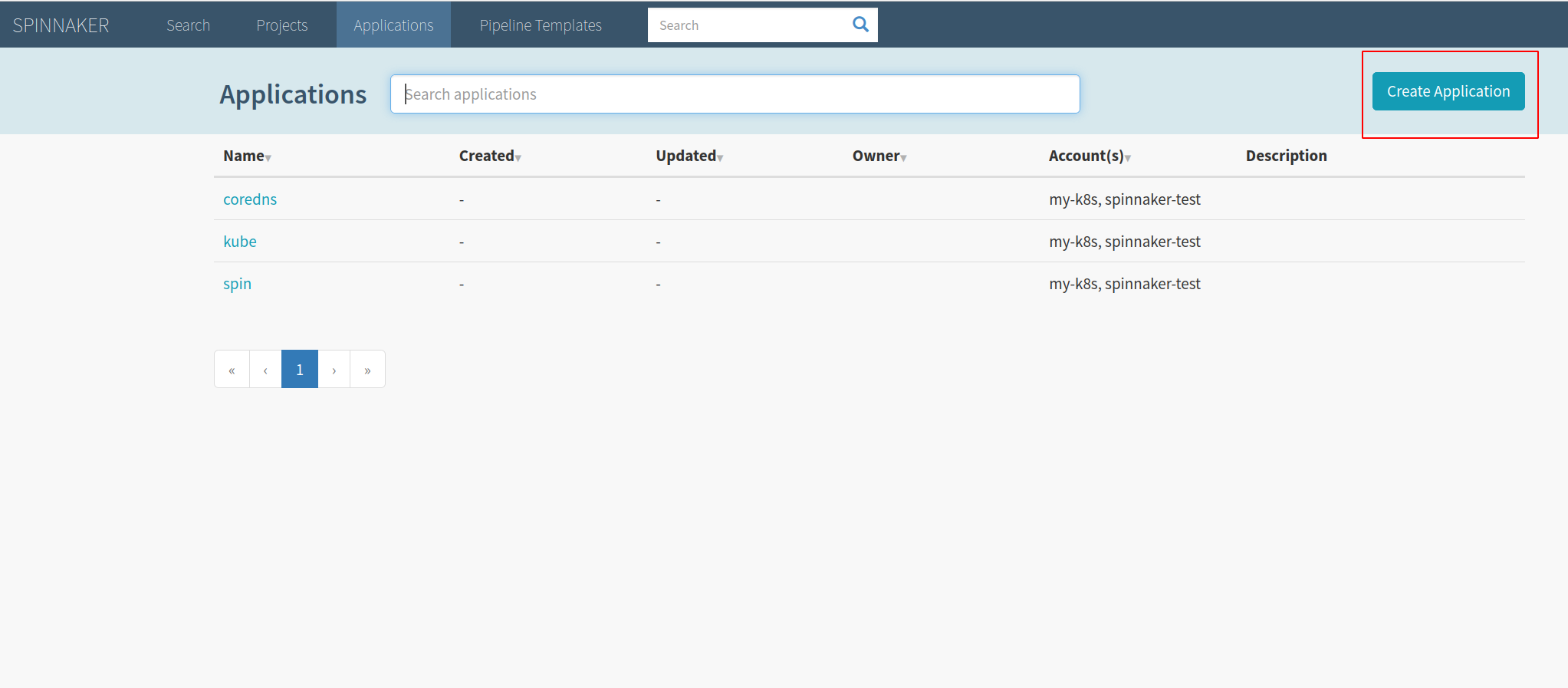
Fill in the details for the service you want to deploy. For our example, we only need to fill in the first two blocks:
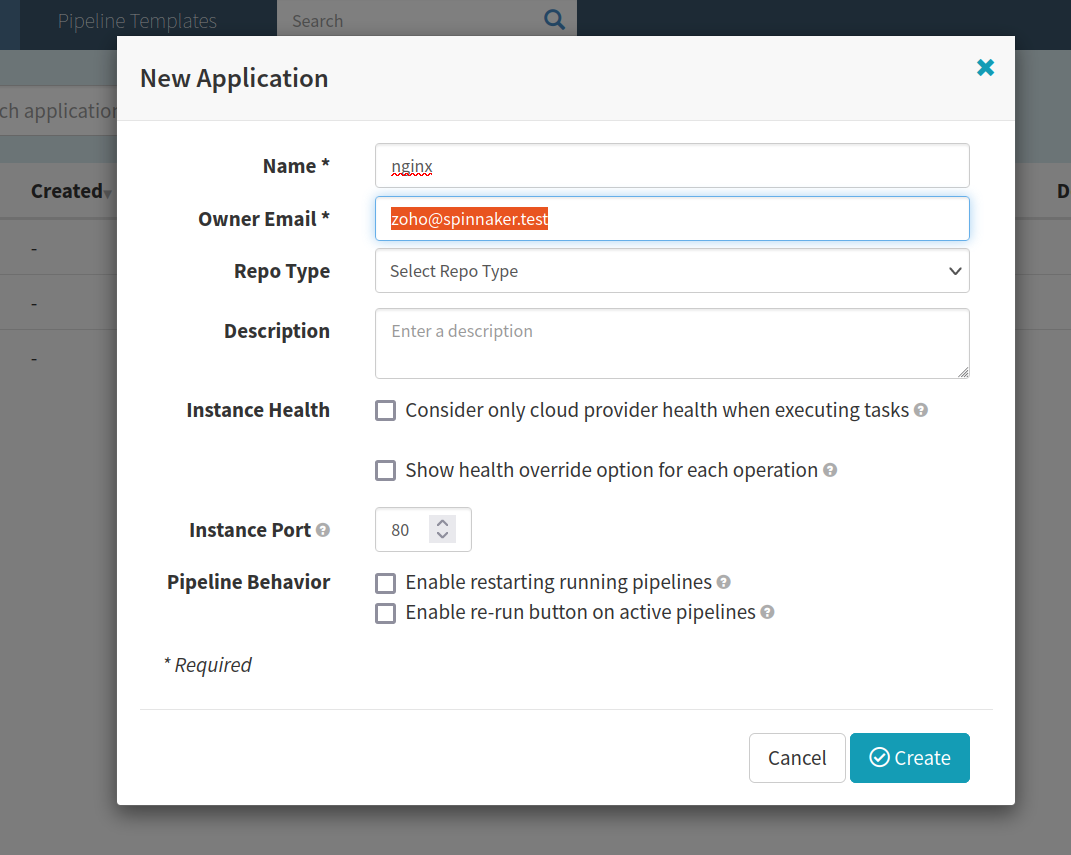
Click on “Create”.
Now, your application will show up on the Applications page. Click on it, and then select “Configure a new pipeline”:
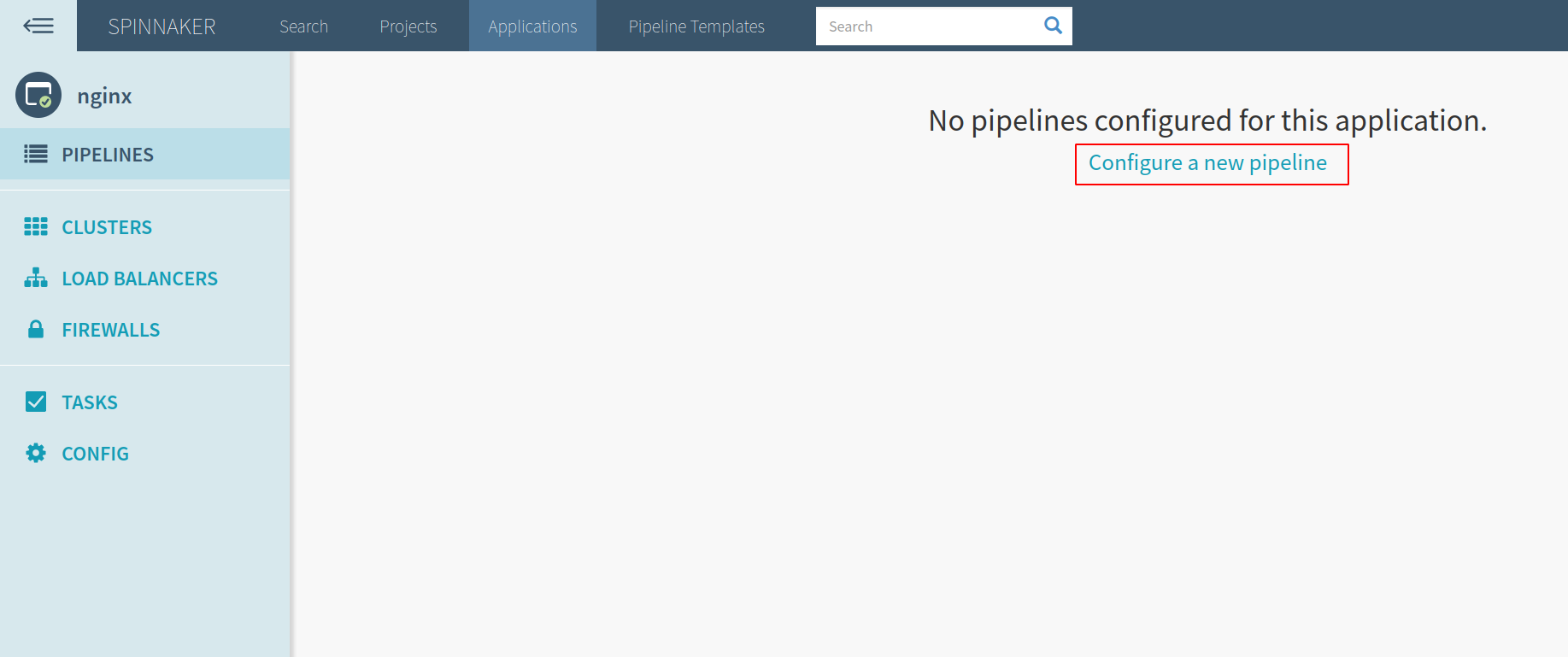
Now, we can add a stage and fill in the details, including the account name and type of stage, which in this case would be “Deploy (Manifest)”. You can also add the deployment file as shown below:
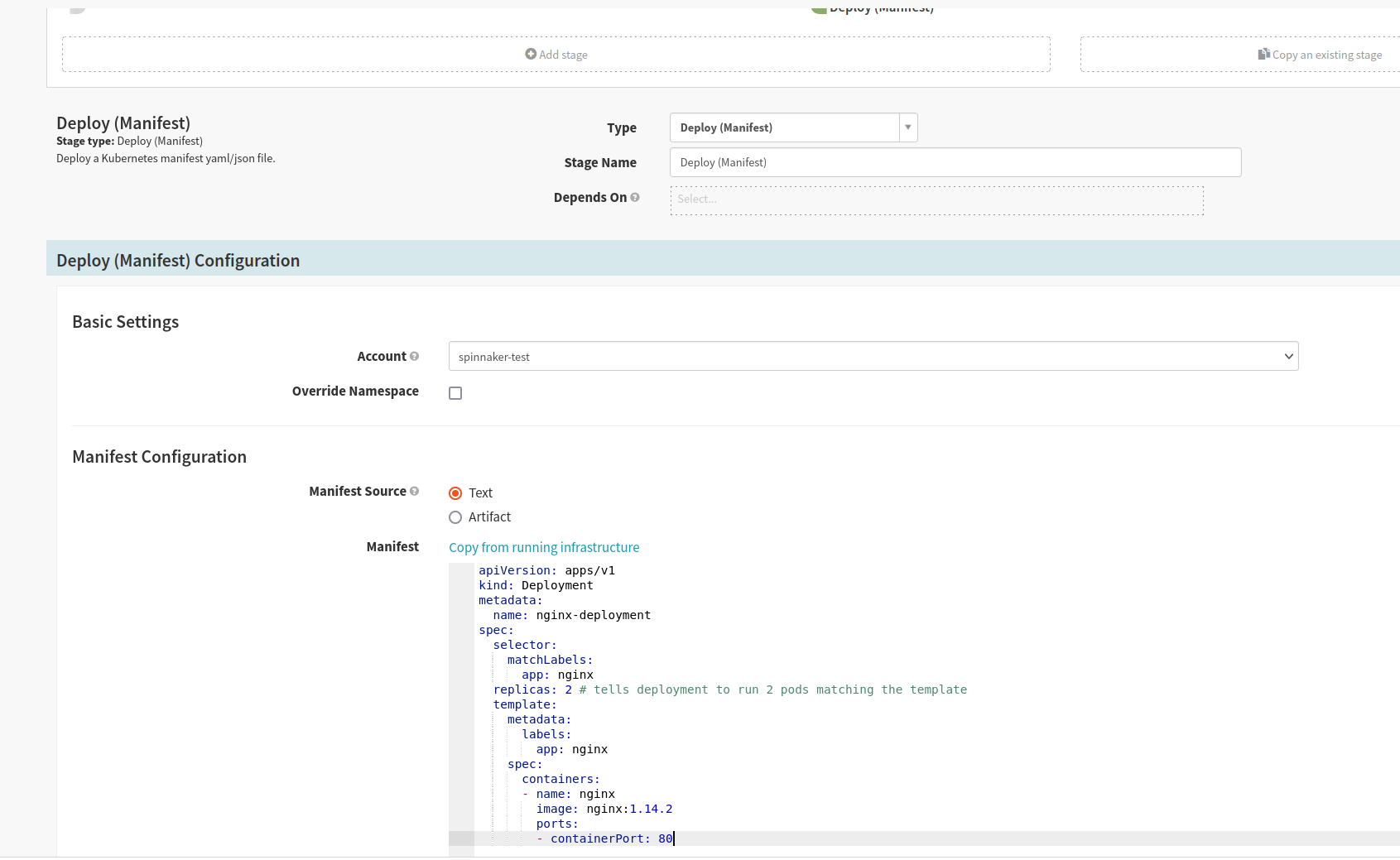
The deployment’s config will be:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: default
spec:
selector:
app: nginx
ports:
- port: 80
targetPort: 80
...
--
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.14.2
name: nginx-container
ports:
containerPort: 80
Save the configuration, and navigate to the Pipelines page. Manually trigger the pipeline, and watch the bar as the pipeline completes in the background:
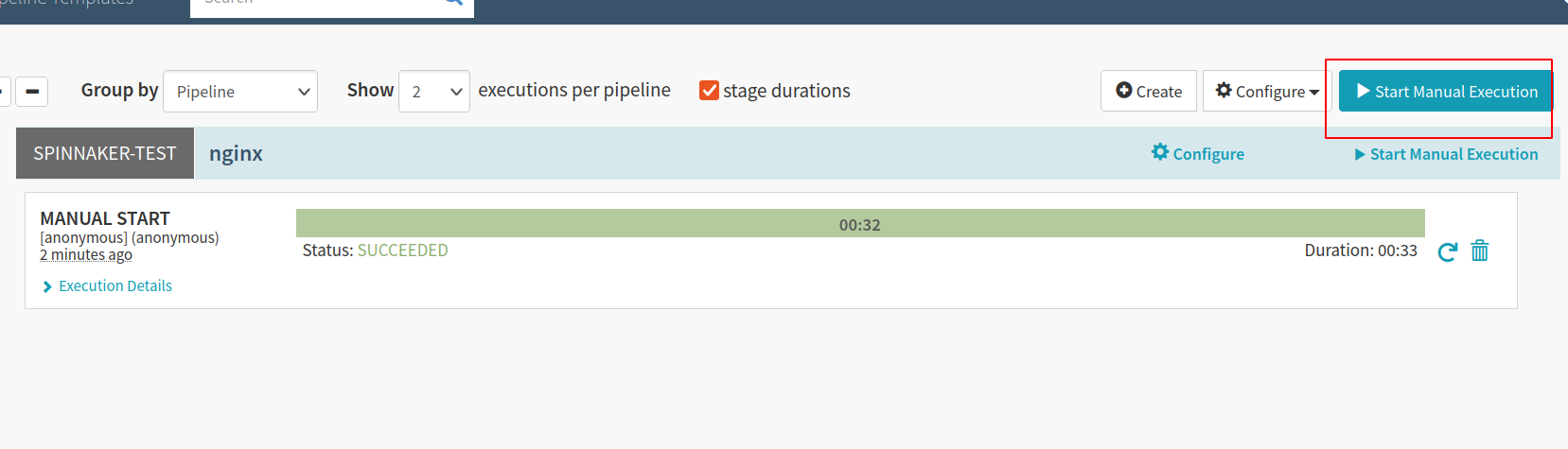
Your NGINX deployment pipeline is now complete and the NGINX app should be deployed in the default namespace.
While Spinnaker is largely used for deploying applications that have pre-built artifacts, it can also be integrated with CI tools such as Jenkins to add build stages in the pipeline. This way, you can plan an entire pipeline around Spinnaker and take advantage of its features.
Compared to other pipeline-based tooling, Spinnaker has certain key advantages:
While Spinnaker is an extremely useful and powerful tool, there are certain things you might want to keep an eye on:
In this blog, we’ve installed Spinnaker from scratch by leveraging Halyard to deploy a sample NGINX deployment in minikube. As seen above, you can easily integrate Spinnaker with major cloud providers, not just Kubernetes.
One of the best use cases for Spinnaker is canary deployments for effective and segregated pipelines to keep your deployments updated with the latest changes.
Considering the pros and cons of Spinnaker is critical for engineers to determine if it’s suitable for the organization and will help them architect effective CI/CD pipelines.
Yes, Site24x7 can monitor the underlying servers, containers, and Kubernetes clusters that host your Spinnaker services, helping you ensure the deployment platform itself remains healthy.
Site24x7 can provide the monitoring data and metrics required to validate canary deployments, ensuring the new version is stable before full rollout.
Yes, Site24x7 offers comprehensive Kubernetes monitoring, giving you visibility into the nodes, pods, and containers deployed by Spinnaker.