Troubleshooting latency issues in event-driven architectures

Particularly, in architectures that are event driven, latency can cause bottlenecks in microservices, impact transaction speeds, and reduce the efficiency of event-driven workflows.
In this blog, we will explore the common causes of latency in event-driven architecture and provide effective troubleshooting techniques. Plus, we will see how Site24x7's application performance monitoring (APM) can help you minimize latency and optimize system performance.
What is event-driven architecture?
Event-driven architecture is a software design pattern where applications respond asynchronously to real-time events, such as user actions, IoT signals, or interservice communications. Unlike traditional request-response models, event-driven architecture ensures scalability by decoupling event producers and consumers.
For example, an online shopping site might send an event when a customer places an order. When processed, this event updates the inventory, sends a confirmation email, and notifies the shipping department—all without waiting for one step to complete before moving to the next.
Core components of event-driven architecture
- Event producers: Generate events (e.g., sensors, user interactions, and microservices).
- Event brokers: Middleware components that route events.
- Event consumers: Services that process events and trigger necessary actions.
- Event store: A repository for logging events for debugging, auditing, and event replay to ensure fault tolerance.
By decoupling components, event-driven architecture enables smooth scaling and independent service updates, reducing disruptions in distributed environments.
Understanding latency in an event-driven architecture
Latency in event-driven architecture refers to the time delay between when an event is triggered and when the system responds. High latency can lead to slow performance, frustrating users and reducing efficiency.
Common causes of latency in event-driven applications
- Network congestion: Heavy traffic or slow network connections delay event transmission.
- Inefficient event processing: Poorly optimized event handlers can increase response times.
- Resource limitations: Insufficient CPU, memory, or bandwidth can slow down event-driven applications.
- Overloaded message brokers: When event brokers are overwhelmed, events may queue up and experience processing delays.
- External API latency: Dependence on third-party APIs that have high response times can increase overall latency.
- Large payloads: Sending large event messages can slow down communication and processing.
- Synchronous dependencies: Components that rely on synchronous calls instead of asynchronous processing can create bottlenecks.
- Lack of caching: Repeatedly fetching the same data from databases instead of using a caching mechanism can slow event processing.
- Security and compliance overhead: Encryption, authentication, and compliance measures, if not optimized, can add extra processing time.
Troubleshooting latency in event-driven architectures
Latency reduction can make event-driven architecture more responsive. Let's look at a few strategies to effectively troubleshoot latency.
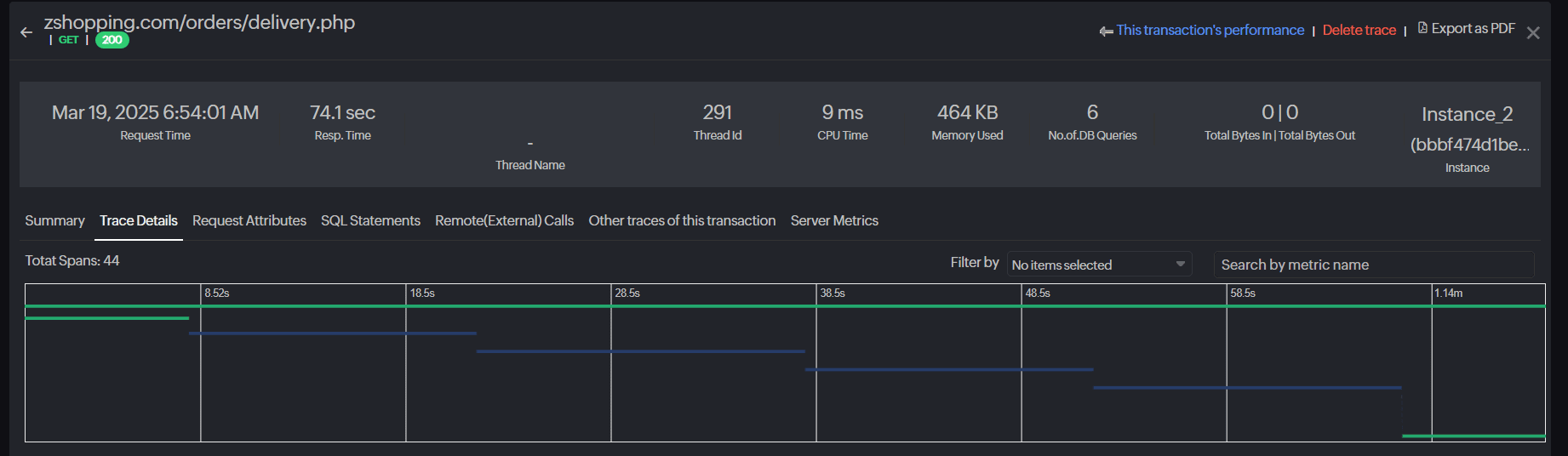
Implement distributed tracing
Event-driven systems often involve complex interactions between microservices and message brokers. Visualize dependencies between services, exposing latency hotspots (e.g., slow database queries or throttled API calls). Track how events move through services to pinpoint slowdowns. Site24x7’s APM provides distributed tracing
that maps event flows across services to uncover bottlenecks and optimize workflows.
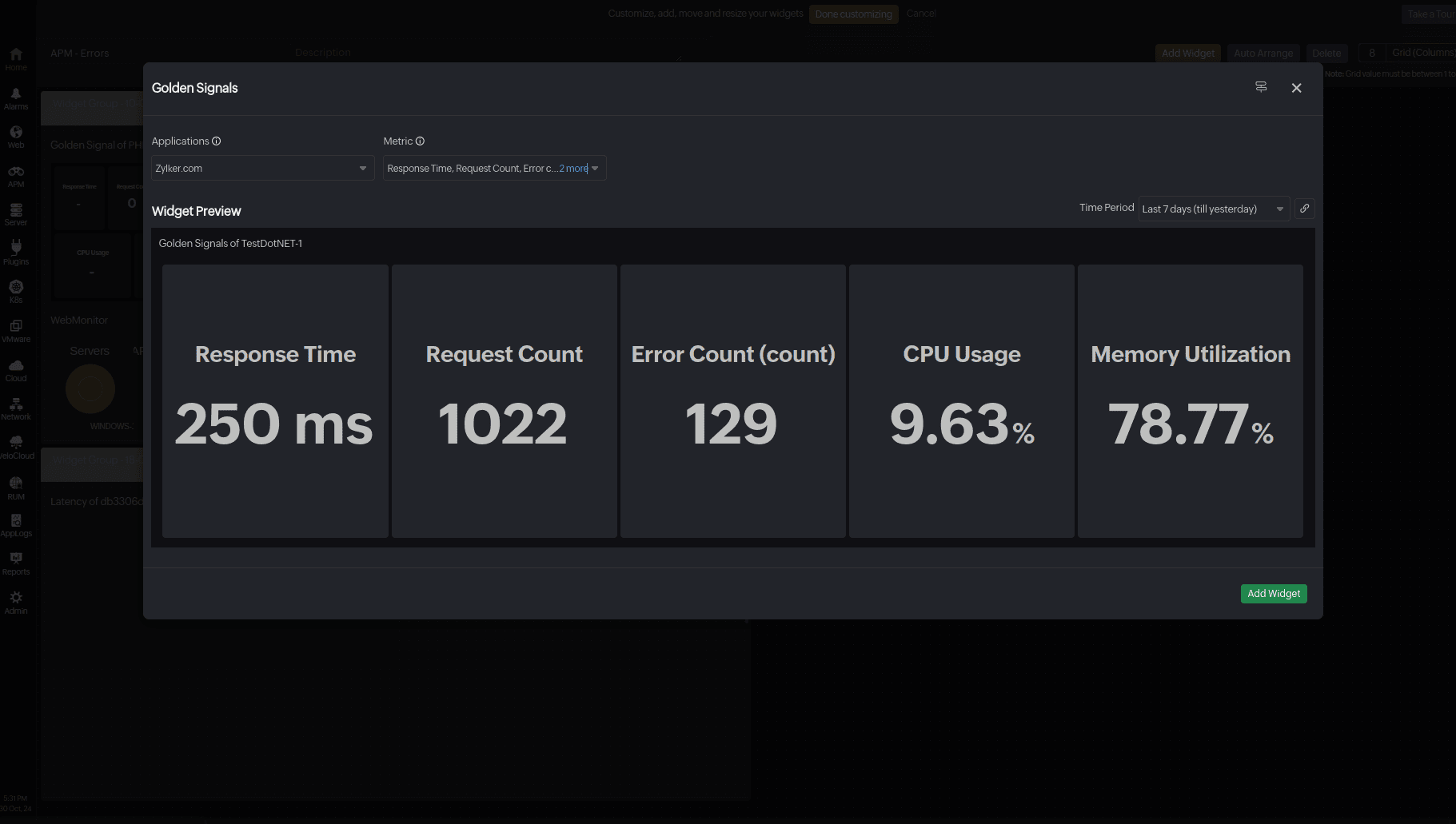
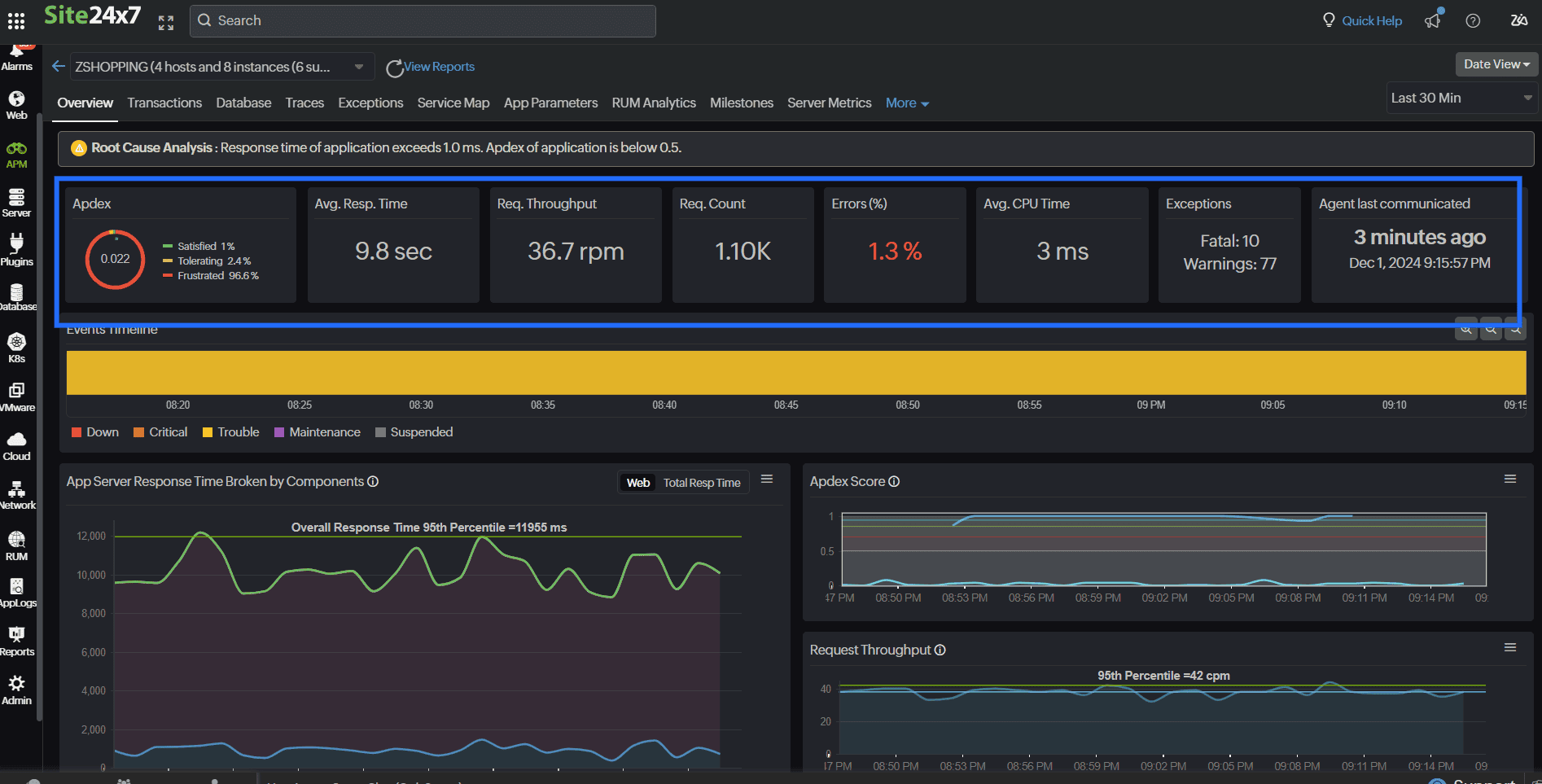
Observe the golden signals
Keep an eye on response times, throughput, and error rates. Site24x7’s APM offers real-time monitoring of various metrics
to detect and resolve performance issues before they impact a larger user base. Correlate latency with application metrics to identify non-compliance with defined SLOs and prioritize remediation measures. Additionally, Site24x7 provides a widget option for a custom dashboard to track your golden signals.
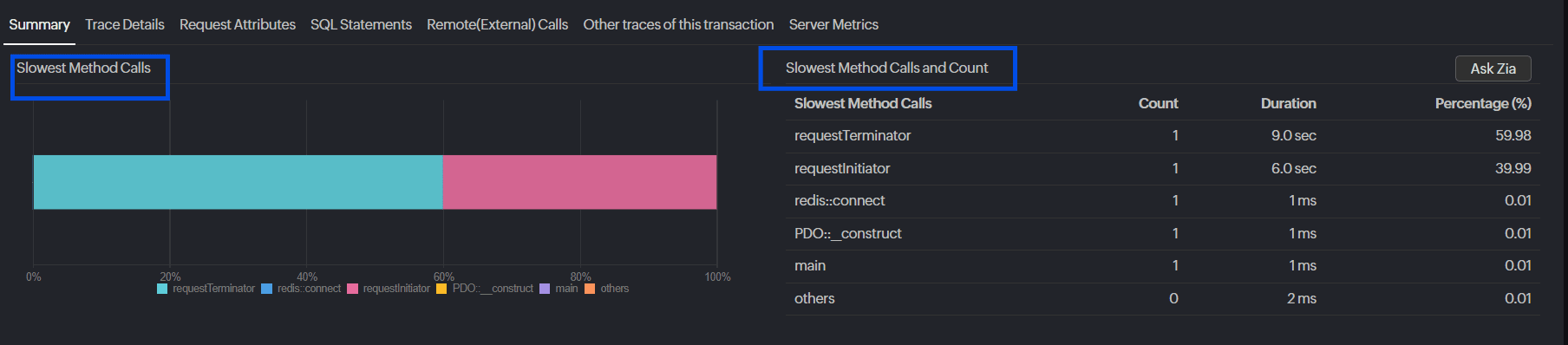
Optimize event processing logic
Eliminating unnecessary computations reduces processing overhead, preventing resource wastage. Site24x7’s code-level insights help pinpoint slow functions, enabling developers to optimize performance; streamline execution; and ensure faster, more efficient event processing.
Mitigate latency with AI-driven features
Site24x7’s AI-powered monitoring tools effectively tackle latency challenges in event-driven architecture by enabling proactive detection, rapid root-cause analysis, and optimization of event-processing workflows. The platform's anomaly detection feature learns seasonal patterns and intelligently flags expected latency spikes, allowing teams to focus on genuine issues. Additionally, Zia Forecast leverages AI to predict resource demands by anticipating event surges and optimizing resource allocation, thereby reducing resource contention.
Ensure proper resource allocation
Insufficient CPU, memory, or network bandwidth can choke performance. Auto-scaling strategies dynamically allocate resources based on real-time demand, preventing slowdowns due to capacity constraints.
Monitor external dependencies
A slow third-party API can introduce cascading latency. Site24x7's APM continuously monitors external dependencies
, alerting you when response times degrade so you can take action quickly.
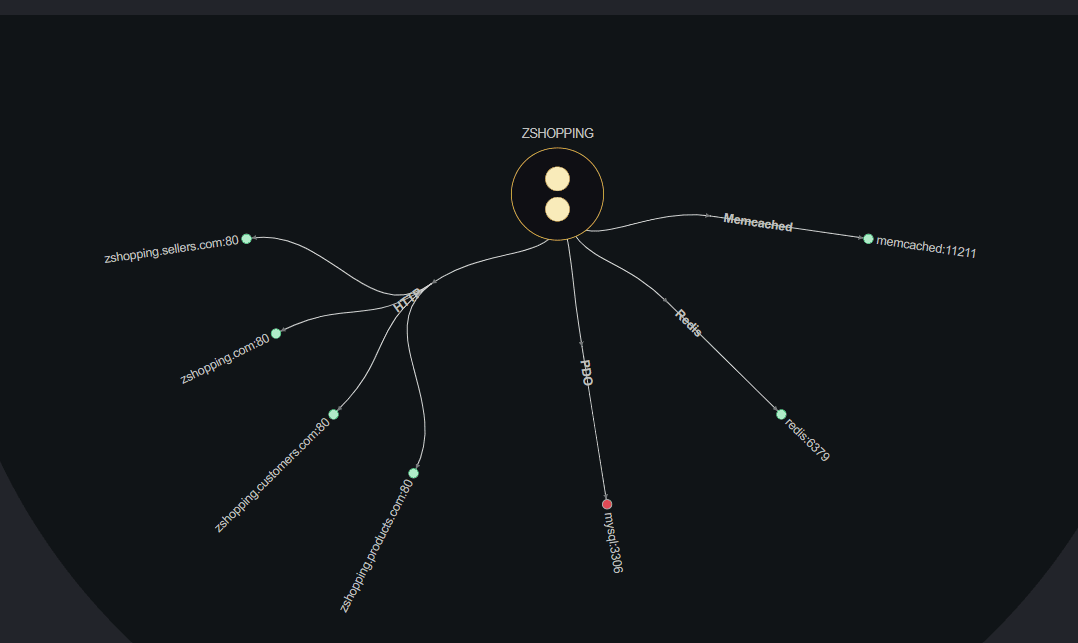
Utilize caching mechanisms
Employ asynchronous processing
Allow multiple events to be processed simultaneously by designing components to handle asynchronous operations efficiently.
Implement efficient error handling
Handle failures gracefully to prevent cascading delays. Site24x7’s APM tracks errors and exceptions in real time, offering insights into their impact on system performance.
Best practices for minimizing latency in event-driven architecture
- Use lightweight event payloads: Keep messages lean for faster transmission.
- Optimize broker performance: Optimize the message broker settings for efficient event handling.
- Implement auto-scaling: Prevent slowdowns during peak usage with auto-scaling.
- Use connection pooling: Optimize database and API connections to avoid connection overhead.
- Deploy monitoring and alerting: Set up real-time monitoring with alerts to detect and resolve latency issues quickly.
- Leverage edge computing: Process events closer to the source to reduce network delays.
These best practices coupled with monitoring can effectively reduce latency in your event-driven architecture, ensuring a responsive and efficient system.