Kubernetes 2024: Challenges and solutions

Kubernetes has become the world's leading container orchestration platform, aiding small-scale to large-scale businesses in automating, autoscaling, and managing application deployments. Before delving deeper, let's understand why cloud-native solutions like Kubernetes have become the world's—especially organizations'—favorite technology.
Creating highly scalable, resilient applications requires flexible infrastructure management. Also, maintaining an entire infrastructure can become burdensome, and the potential for the operational expenditure to skyrocket has led modern IT operations and businesses to adopt cloud-native technologies like containers, microservices, Docker, and Kubernetes.
The ease of management and the cost-cutting flexibility have made this choice more desirable. This cloud-native approach has empowered organizations to leverage productivity with the improved agility, scalability, and reliability of their applications.
With Kubernetes, you can build highly scalable, flexible, resilient applications that can be updated and expanded according to your growing customer base's needs to meet any dynamic, sudden surge and your upscaling productivity. You will have nothing else to worry about—not the maintenance of the infrastructure nor the need to buy more servers when the business expands.
This is convenient but does come with its own set of challenges. Let's look at them in this article, along with the solutions that help resolve them.
Challenges of Kubernetes and their solutions
Kubernetes in itself is a complex architecture with all its clusters and the individual workloads, Nodes, Pods, containers, and applications running with it. When the orchestration fails for some reason, and the application deployment doesn't happen, identifying the root cause within a stipulated time and solving the problem become challenging. Here are some of the most pressing Kubernetes challenges and some preventative strategies that will help you handle them.
1. A lack of centralized visibility
In a Kubernetes cluster environment, which is resource-intensive, congestion can occur because of the ever-expanding workloads and distributed applications, making it challenging to process, analyze, and fathom the functional algorithms of the environment itself.
Having the ability to visualize your cluster's landscape through a single, unified console with clear reports, alarms, and health dashboards is paramount for swiftly identifying and fixing issues. This visionary approach aids in preventing performance degradation crises and outages.
2. Infrastructure complexity
Kubernetes containers and multi-cloud hybrid ecosystems like the Azure, GCP, and AWS virtual infrastructure platforms are complicated by themselves. Kubernetes has made its already complex infrastructure more intricate with its short-lived, smaller components and resources; thus, managing the infrastructure becomes mountainous at times.
The complete management of Kubernetes using full-fledged monitoring tools and strategies like automating remedial actions when a predefined threshold is crossed will aid in lowering downtime and preventing bottlenecks, thereby cutting down on incident management costs.
You should ensure that the tool you choose supports Kubernetes monitoring in diverse environments as well as integrations with tools like Slack, Zapier, Jira, Microsoft Teams, ManageEngine ServiceDesk Plus, Zendesk, Zoho Analytics, and Amazon EventBridge for sounder dexterity. This is one of the foremost strategies employed by enterprises to simplify Kubernetes management, reduce risks, and boost productivity.
3. Networking failures
Modern, complex computing requirements abound in large-scale, multi-cloud, multilayered, back-to-back deployments. Networking is inevitable for communication between every single workload, and there are millions of transactions that happen in a single second. This results in clouded network visibility, which makes managing the network landscape tedious. If an organization still uses the conventional method of managing its network with static IPs and ports, it will fall short in upscaling its deployments using a dynamic orchestrator like Kubernetes.
Network visibility plays a dominant role in orchestrating the deployment process smoothly. You can overcome unidentified network failures by monitoring network-specific KPIs like the network availability, network utilization, amount of data transmitted, amount of data received, and data-ingress-level stats.
4. Outrunning resource utilization
Resource management can get out of hand at times when it comes to Kubernetes. A microservices architecture, with all the intricate components and applications running in it, is more prone to this endangering jeopardy of resources getting jammed, resulting in bottlenecks, performance degradation, and outages.
Tracking Kubernetes metrics is the key to ensuring efficient resource management and the optimal availability of Kubernetes resources. Other solutions that cater to solving resource inefficacy are AI-driven forecasting (which predicts resource needs and proactively addresses inefficiencies) and capacity planning (which determines the capacity required to optimize resources for a particular workload).
5. Cluster instability
A container is not a static entity; it can be altered, upscaled, modified, downscaled, and repurposed. This applies to other dynamic resources, too. This dynamic behavior poses a threat to the entire cluster operation, causing instability. Large-scale, distributed applications may face potential reliability issues because of cluster instability.
Addressing this requires the implementation of logging and tracing mechanisms as well as robust monitoring of Kubernetes clusters with all their workloads, events, and applications. This way, the cluster admins can ensure cluster stability and foresightedly prevent failures.
6. Threats to business continuity
No business should risk its fortune when it comes to security. Deployment on Kubernetes can be as smooth as butter when the entire Kubernetes infrastructure is as secure as an iron vault. Security can be compromised because of configuration errors and mismanagement, leading to unidentifiable issues that, in turn, also affect the entire workflow of the application deployment.
Identifying vulnerabilities in workloads and servers is paramount. Keeping track of the overall metrics, events, traces, and logs can prove indispensable. Proactive alerting and troubleshooting ensure the optimal, secure functioning of the entire infrastructure. This, in turn, protects your business continuity from deviating risks and mishaps.
To conclude
A Kubernetes monitoring tool that supports full-stack observability is all you need to cater to the growing needs of the complex infrastructure. Intuitive, customizable dashboards catering to different business requirements and in-depth reports showing the health and performance of your entire cluster infrastructure will help you analyze performance trends and proactively identify potential threats.
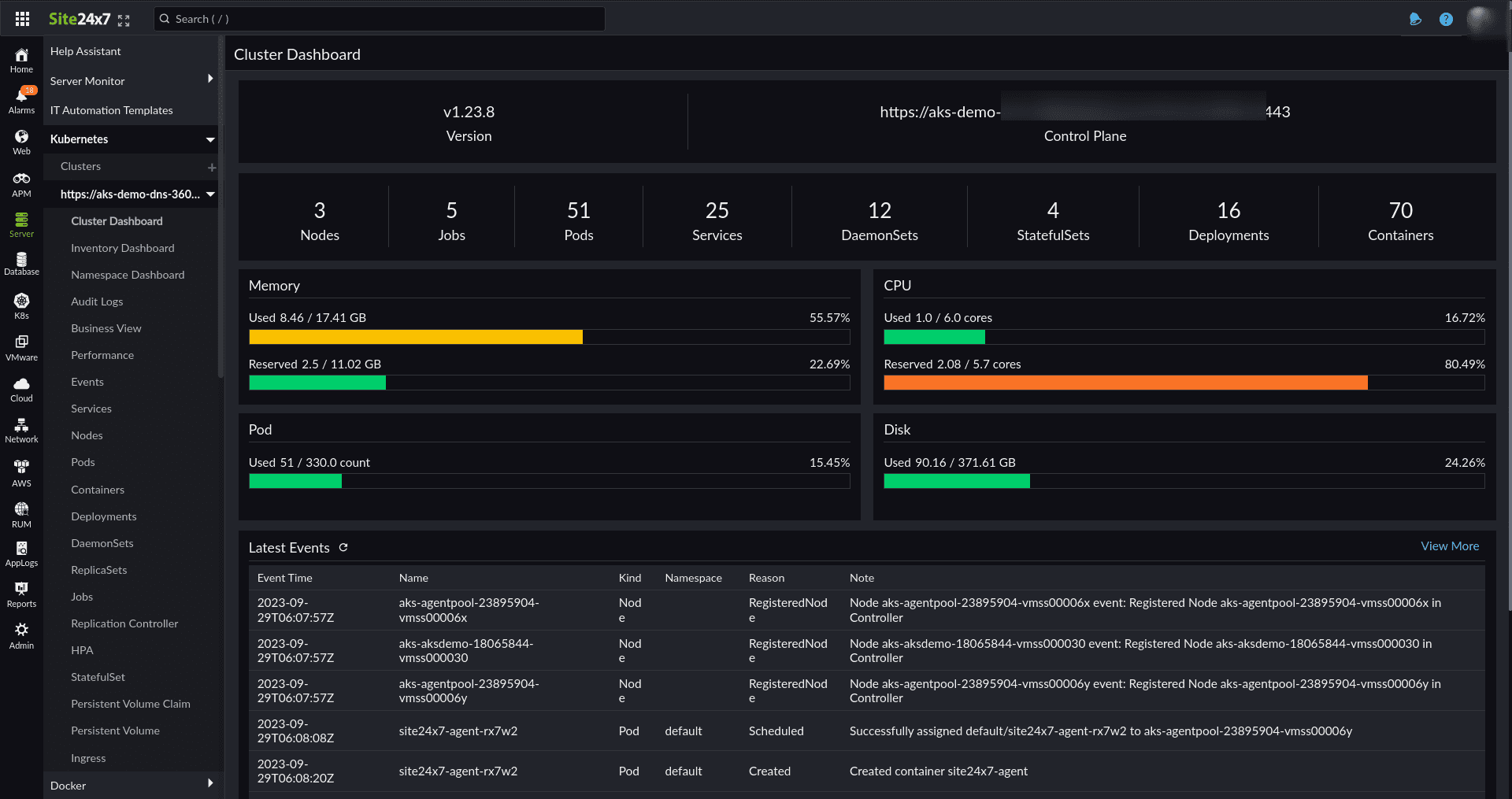
Metrics help you obtain maximum visibility into the Kubernetes infrastructure, including the KPIs of the cluster components, Nodes, and Pods; deployment data; and storage.
Logging and tracing are added advantages when the monitoring platform has them in one way or another. Kubernetes logs, encompassing Pod logs, audit logs, event logs, application logs, and activity logs, aid in diagnosing and addressing any issues affecting the applications operating within the environment. Tracing is key when it comes to monitoring and debugging applications deployed on Kubernetes. It also empowers DevOps engineers to monitor application performance closely, pinpoint issues, and troubleshoot problems.
Explore our Site24x7 Kubernetes monitoring tool, the complete, AI-powered Kubernetes observability tool that provides 24/7, 360-degree monitoring and management of Kubernetes clusters and microservices.
Comments (0)